Cross-compile for each target with Apache TVM, distribute across your KubeEdge fleet, and hot-swap the running model with one API call. No per-device SSH loop.
Most teams stitch together a registry, a build farm, an OTA system, and a metrics stack. Aina is one coherent platform for all of it.
Deploy a new model and the device swaps what it serves on its own. The edge runtime reloads the new graph and resumes. No scp, no SSH, no manual restart.
Cross-compile your ONNX model — classification, detection, super-resolution, even speech encoders — with Apache TVM for x86 or ARM64. MetaSchedule autotunes the kernels to the device (~7× faster inference, measured) before you ship.
Compilation and deployment run as NATS JetStream jobs with retries. If the backend restarts mid-flight, stuck jobs recover on their own. Submit and walk away.
Compilation runs as Kubernetes Jobs; the edge runtime ships as a DaemonSet on your KubeEdge nodes. The whole stack installs from one Helm chart.
Built for intermittent links and constrained devices. Runs on KubeEdge nodes; each device pulls its model on demand through a short-lived presigned URL.
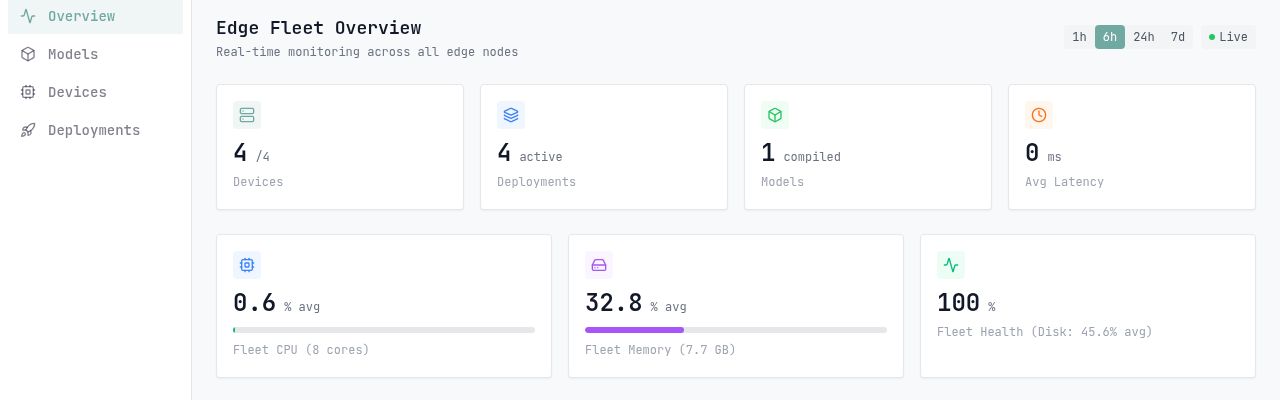
Per-device inference latency, throughput, errors, model-load time, and CPU/memory/disk, exported in Prometheus format and rendered on the dashboard.
Live device health, per-node inference metrics, and one-click compile — all in one place.
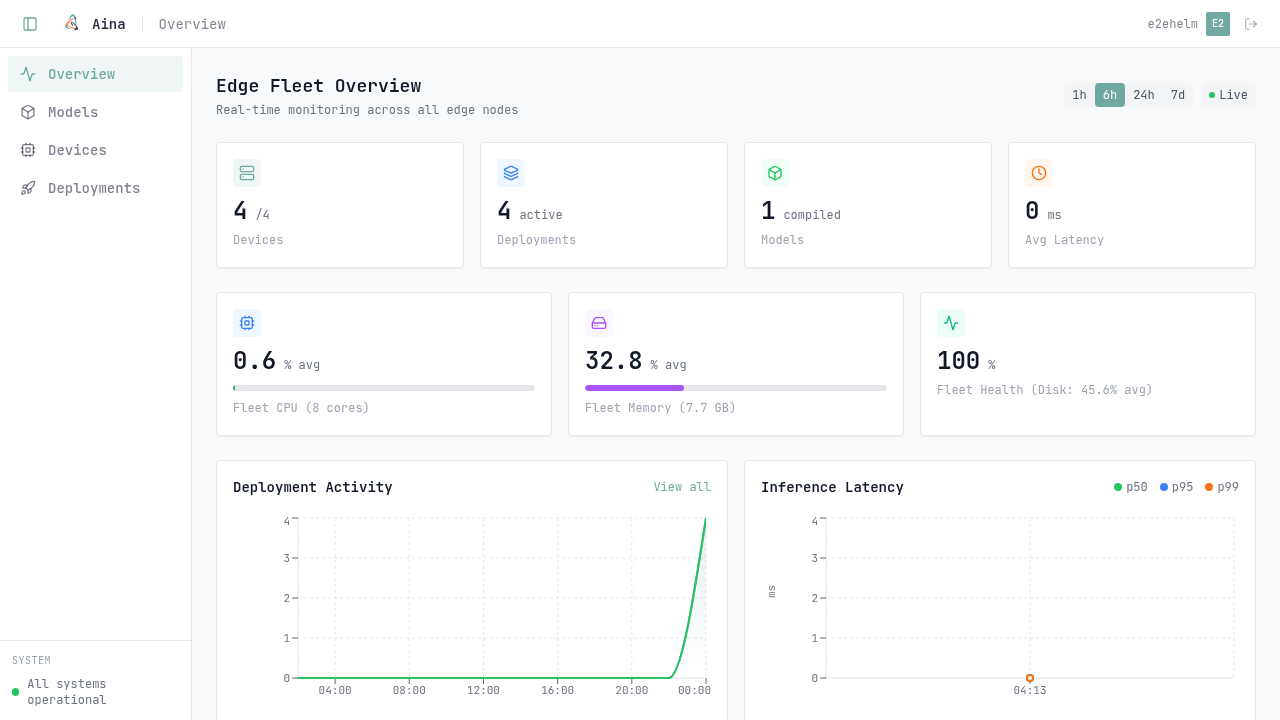
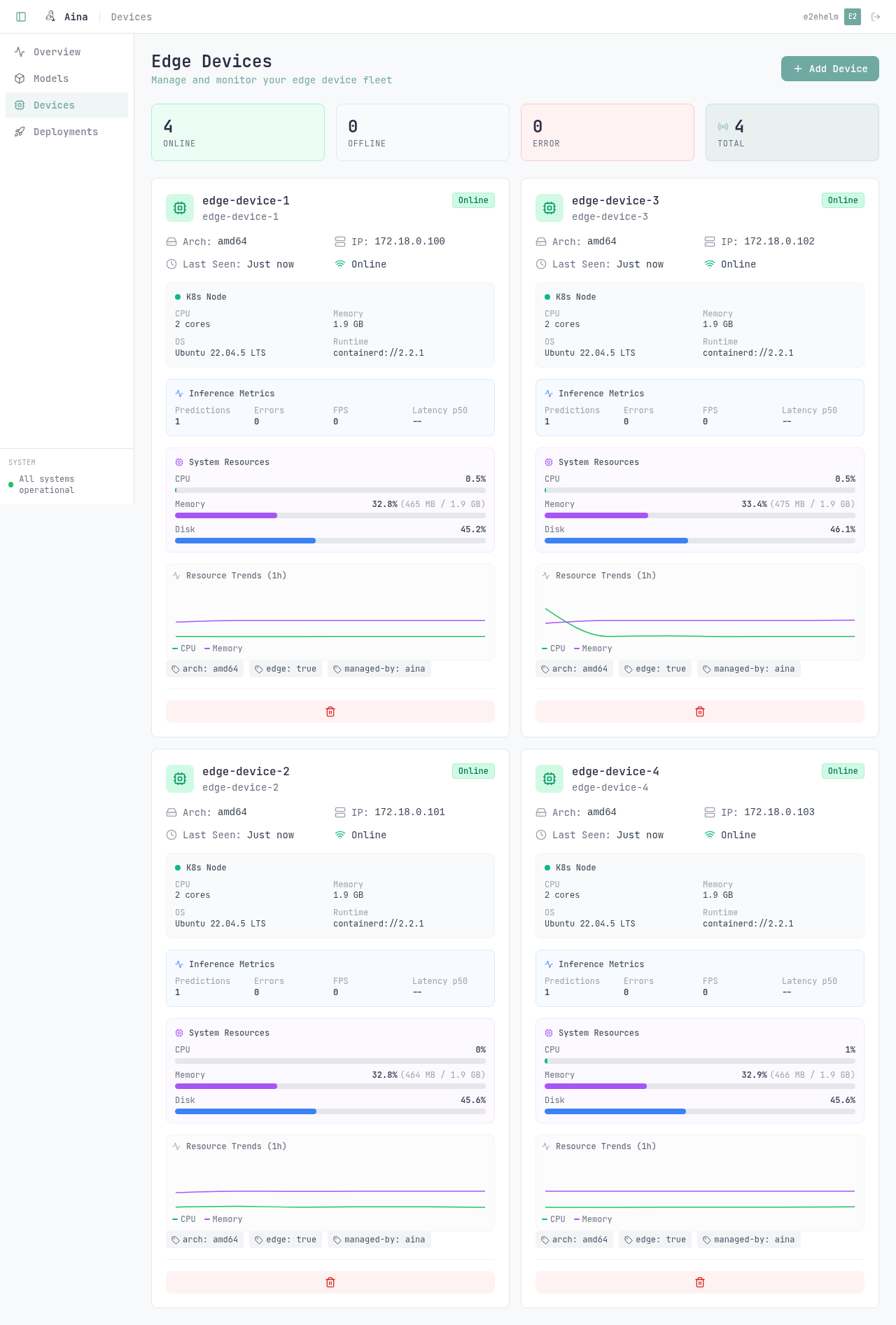
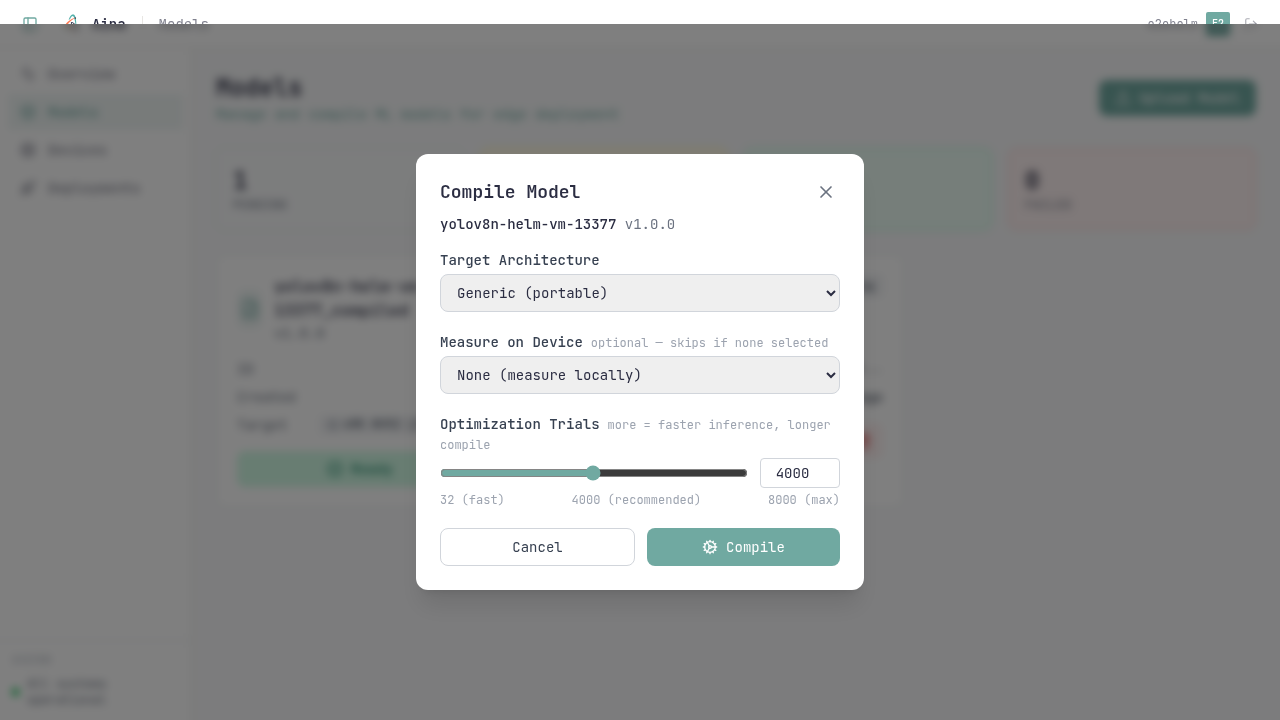
aina push to live inference, in one flow.Four stages, one flow. Click through to see what each one does.
Push a model artifact to Aina. It is stored in object storage and versioned by name.
Aina spawns a Kubernetes Job that compiles the model with Apache TVM and autotunes the kernels to your target with MetaSchedule. Progress streams live.
Create a deployment and start it. A NATS JetStream job hands the device a short-lived presigned URL; the device pulls the model over HTTP — a path that survives flaky uplinks and offline windows.
The device reloads the new model and resumes serving, no SSH required. Roll back at any time with aina deploy stop / start.
The edge runtime exports a Prometheus endpoint on every node. Prometheus scrapes it; the dashboard queries it. Plug it into Grafana or scrape it raw. Nothing proprietary, nothing locked in.
We kept watching teams hand-roll the same fragile glue — a registry, a build farm, an OTA system, scripts that SSH into devices to swap models with a 3am restart. So we built the platform we wanted instead.